


地址:上海市宝山区长江软件园
电话:191 2100 2160

微信联系我们
2023-11-13
来源:上海百沐生物科技有限公司
所属分类:单细胞测序100问
完成序列比对和基因注释后,基因组数据通常被总结为一个特征矩阵。这个矩阵的形状是number_observations x number_variables,其中观察值是细胞条形码,变量是注释基因。在分析过程中,这个矩阵的观察值和变量会被注释上计算得出的测量值(例如质量控制指标或潜在空间嵌入)和先验知识(例如源供体或替代基因标识符)。在scverse生态系统中,AnnData将数据矩阵与这些注释关联起来。为了实现快速和内存高效的转换,AnnData还支持稀疏矩阵和部分读取。
虽然AnnData与R生态系统中的数据结构(例如Bioconductor的SummarizedExperiment或Seurat的object)大体相似,但R包使用的是转置的特征矩阵。
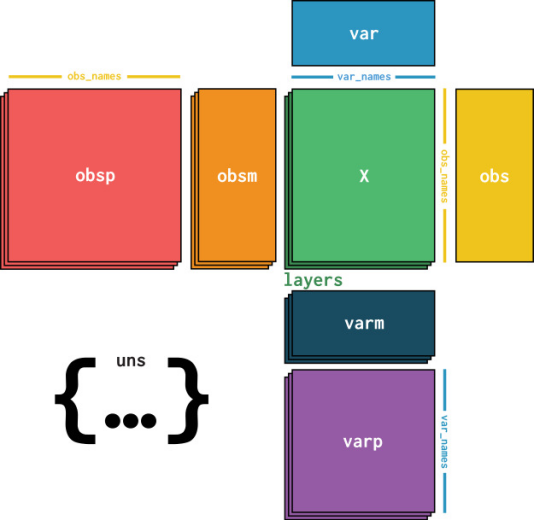
AnnData对象的核心是在X中存储稀疏或密集矩阵(scRNA-Seq中的计数矩阵)。这个矩阵的维度是obs_names x var_names,其中obs(观察值)对应于细胞的条形码,var(变量)对应于基因标识符。这个矩阵X被Pandas DataFrames obs和var包含,它们分别保存细胞和基因的注释。此外,AnnData保存了完整的计算矩阵,用于观察值(obsm)或变量(varm),并具有相应的维度。通常将细胞与细胞或基因与基因关联的图形结构保存在obsp和varp中。任何不适合其他slot的非结构化数据都保存在uns中。还可以在layers中存储更多的X值。这样做的用例包括在counts层中存储原始的、未标准化的计数数据,在未命名的默认层中存储标准化数据。
AnnData主要设计用于单模态数据(例如scRNA-Seq)。然而,AnnData的扩展,如MuData,允许高效存储和访问多模态数据。
 在线咨询
在线咨询 微信咨询
微信咨询
 电话咨询
电话咨询
联系电话:191 2100 2160
 顶部
顶部